SADMA: Scalable Asynchronous Distributed Multi-Agent Reinforcement Learning Training Framework
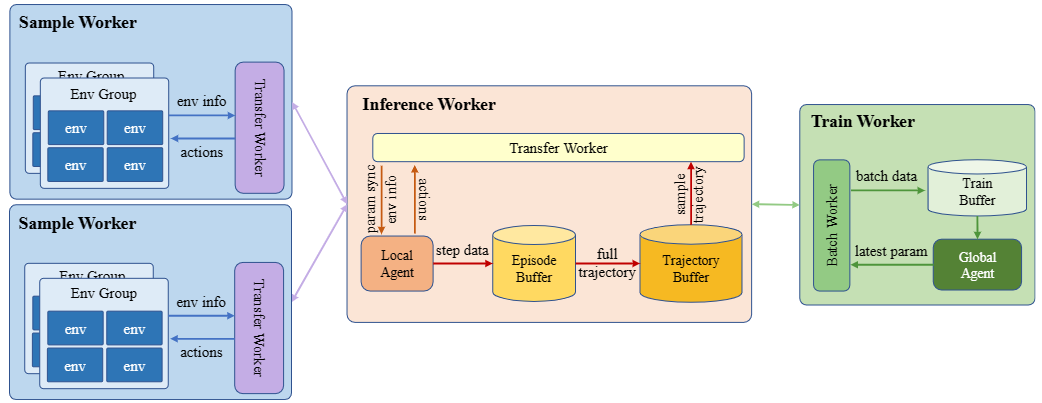
Abstract
Multi-agent Reinforcement Learning (MARL) has shown significant success in solving large-scale complex decision-making problems while facing the challenge of increasing computational cost and training time. MARL algorithms often require sufficient environment exploration to achieve good performance, especially for complex environments, where the interaction frequency and synchronous training scheme can severelylimit the overall speed. Most existing RL training frameworks, which utilize distributed training for acceleration, focus on simple single-agent settings and are not scalable to extend to large-scale MARL scenarios. To address this problem, we introduce a Scalable Asynchronous Distributed Multi-Agent RL training framework called SADMA, which modularizes the training process and executes the modules in an asynchronous and distributed manner for efficient training. Our framework is power fully scalable and provides an efficient solution for distributed training of multi-agent reinforcement learning in large-scale complex environments.
Flexible Resource Allocation
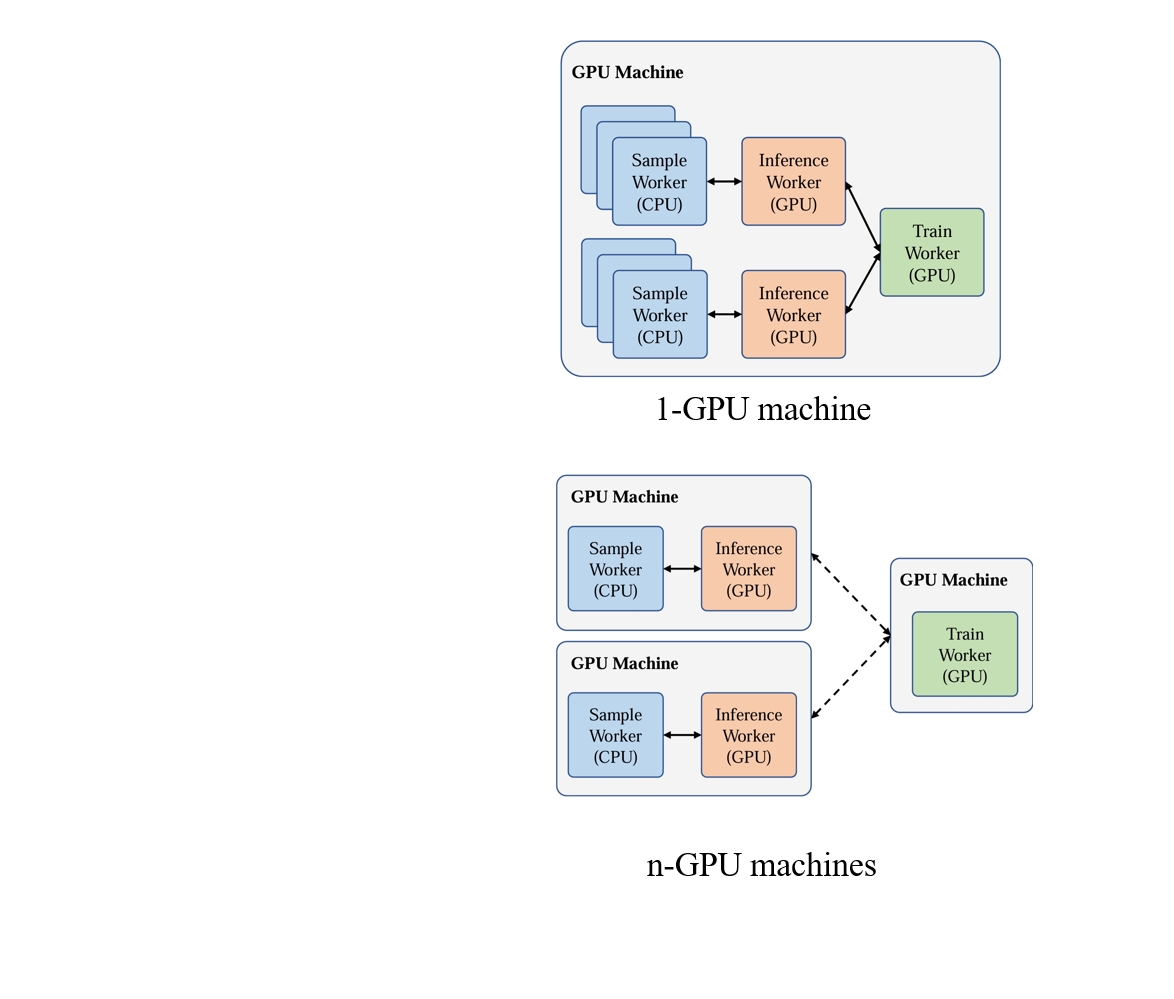
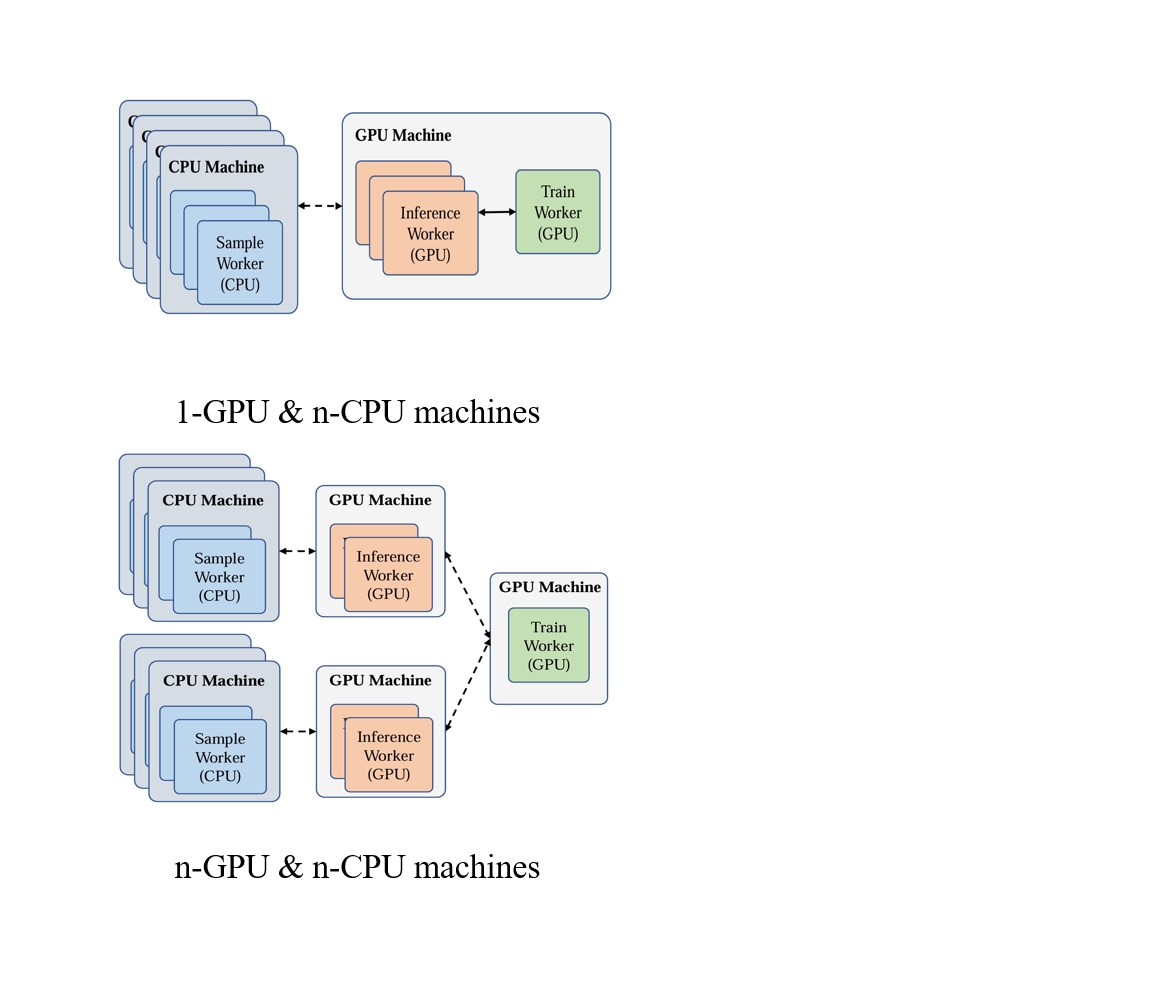
Experiments
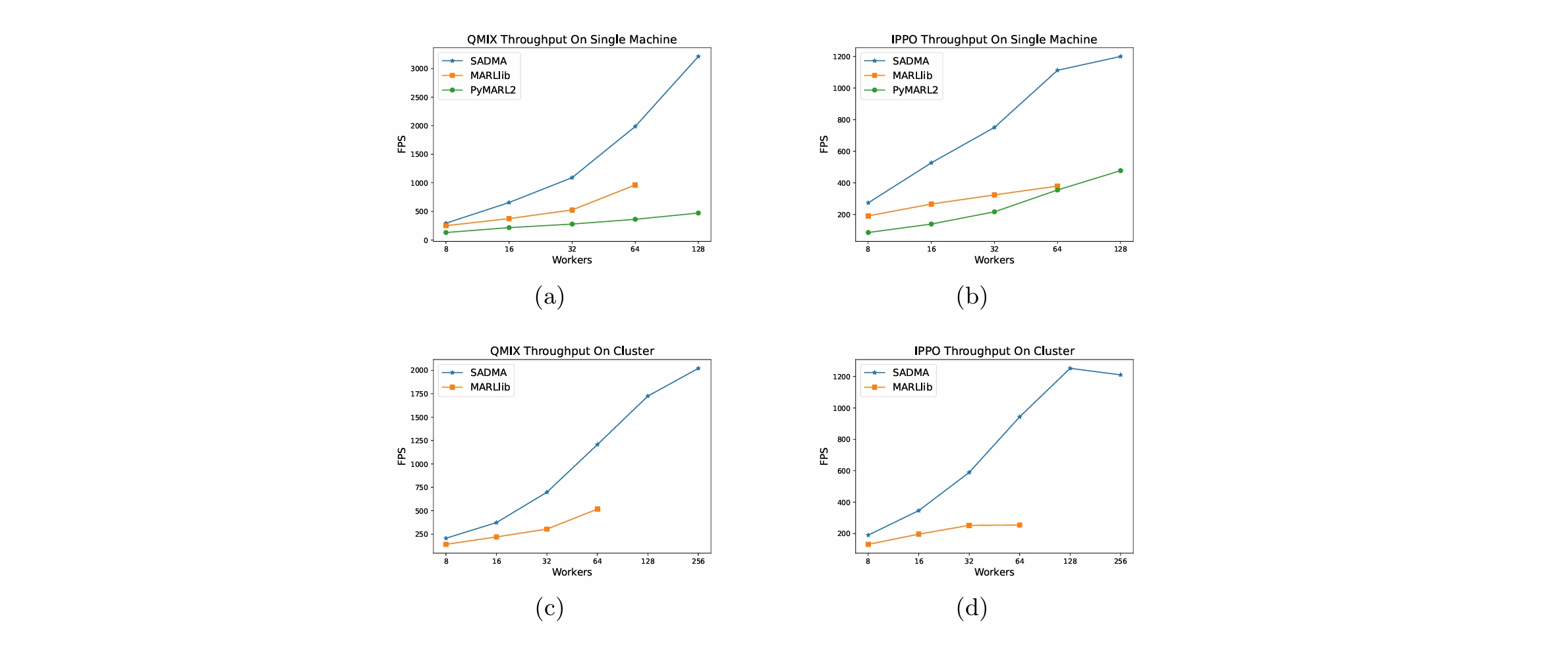
Throughput Comparisons
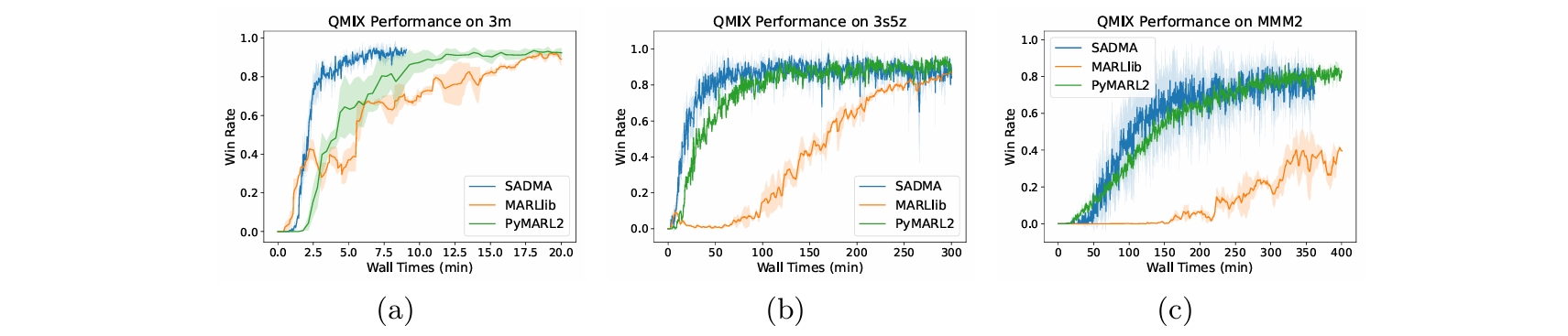
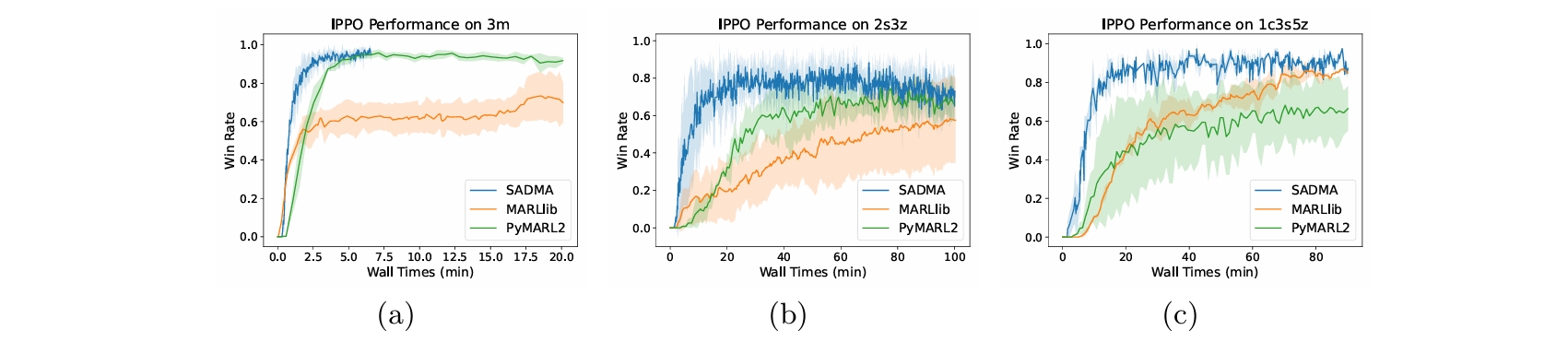
Convergence Acceleration
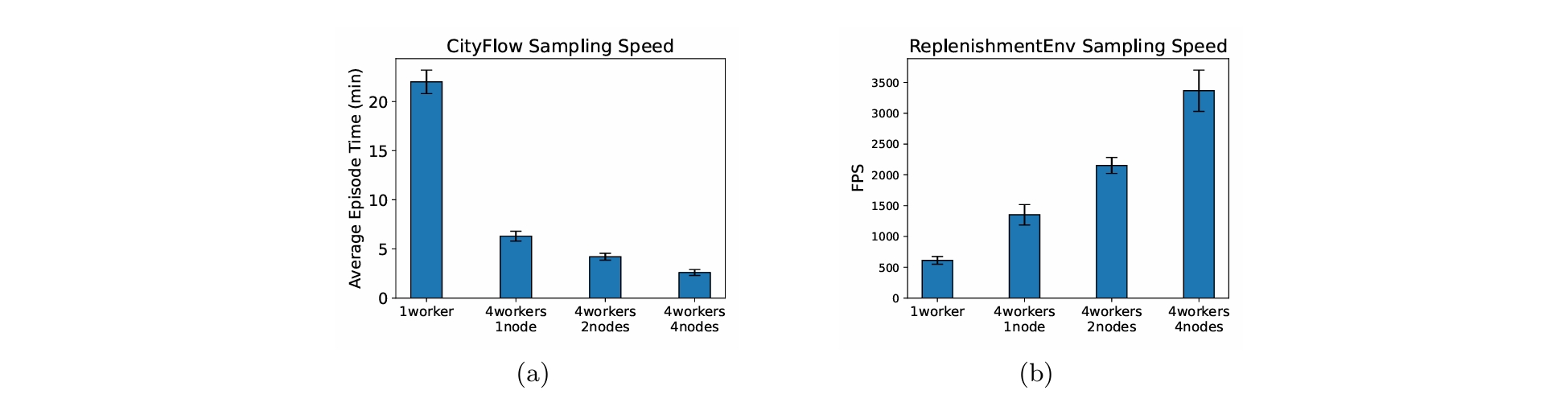
Scalability Evaluation
Citation
wang2024SADMA,
title={SADMA: Scalable Asynchronous Distributed Multi-Agent Reinforcement Learning Training Framework},
author={Sizhe Wang, Long Qian, Cairun Yi, Fan Wu, Qian Kou, Mingyang Li, Xingyu Chen, Xuguang Lan},
booktitle={12th International Workshop on Engineering Multi-Agent Systems},
year={2024},
url={https://link.springer.com/chapter/10.1007/978-3-031-71152-7_4}
}
Wang, S., Qian, L., Yi, C., Wu, F., Kou, Q., Li, M., Chen, X., Lan, X. SADMA: Scalable Asynchronous Distributed Multi-Agent Reinforcement Learning Training Framework. In Proceedings of 12th International Workshop on Engineering Multi-Agent Systems Co-located with AAMAS 2024, pages 31-47, Auckland, New Zealand, May. 2024. URL https://link.springer.com/chapter/10.1007/978-3-031-71152-7_4.